58 同城(chéng)深度學習(xí)平台,是集開發實驗、模型訓練和(hé)在線預測爲一體的(de)一站式算(suàn)法研發平台,旨在爲各業務部門賦能 AI 算(suàn)法研發能力,支撐了(le) 58 同城(chéng)搜索、推薦、圖像、NLP、語音(yīn)、風控等 AI 應用(yòng)。作爲中國最大(dà)的(de)生活信息服務商,58 同城(chéng)不斷在提高(gāo)深度學習(xí)平台性能,提高(gāo)平台資源使用(yòng)率,從而更好的(de)提升用(yòng)戶體驗。

58 同城(chéng)探索了(le)在基于第二代英特爾® 至強® 可(kě)擴展處理(lǐ)器的(de) CPU 服務器上進行推理(lǐ)優 化(huà),并進行了(le)測試。測試數據顯示,CPU 服務器在部分(fēn)場(chǎng)景下(xià)能夠實現比 GPU 服務器 更高(gāo)的(de)推理(lǐ)性能,同時(shí)在 TCO、部署靈活性等方面更具優勢。在計算(suàn)機視覺領域的(de)強 勁算(suàn)力需求下(xià),也(yě)能夠可(kě)靠的(de)支撐快(kuài)速增長(cháng)的(de)業務需求。
背景:58 同城(chéng)使用(yòng)在線推理(lǐ)爲用(yòng)戶提供精準服務
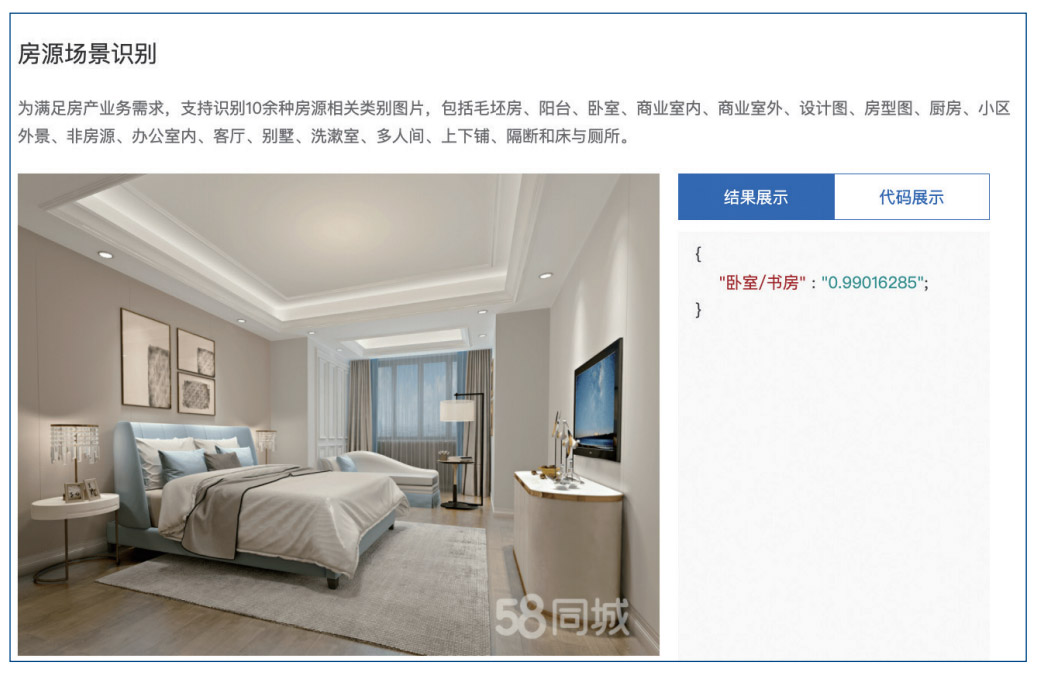
58 同城(chéng)的(de)業務廣泛涵蓋招聘、房(fáng)産、車輛、兼職、黃(huáng)頁等海量的(de)生活分(fēn)類信息,随著(zhe) 各個(gè)業務線業務的(de)蓬勃發展,58 同城(chéng)上的(de)分(fēn)類信息呈現出爆炸性增長(cháng)的(de)趨勢。對(duì)不同 場(chǎng)景下(xià)的(de)需求做(zuò)好分(fēn)類信息處理(lǐ),已成爲一個(gè)重要問題。以房(fáng)産場(chǎng)景爲例,用(yòng)戶每天會 上傳大(dà)量的(de)房(fáng)源相關圖片,系統如何根據用(yòng)戶上傳的(de)海量圖片信息,精準快(kuài)速的(de)進行識 别與分(fēn)類,是提升用(yòng)戶體驗、增加業務收益的(de)關鍵。
爲了(le)提高(gāo)深度學習(xí)平台在線推理(lǐ)的(de)性能,同時(shí)盡可(kě)能降低系統的(de)總體擁有成本(TCO), 目前,基于深度學習(xí)模型的(de)預測服務優化(huà)已經成爲了(le)一個(gè)重 要方向。在圖像領域的(de)算(suàn)法模型中,如 ResNet、CRNN、 YOLOv5 等,都對(duì)硬件算(suàn)力有較大(dà)的(de)需求。如果采用(yòng) GPU 服 務器來(lái)進行深度學習(xí)模型推理(lǐ),将涉及到專用(yòng) GPU 硬件的(de)采 購(gòu),以及配套的(de)搭建、運維等成本,不僅靈活度較低、應用(yòng)範 圍受限,而且也(yě)可(kě)能會帶來(lái)較高(gāo)的(de) TCO 壓力。同時(shí),在 GPU 服務器上進行深度學習(xí)推理(lǐ)往往需要複雜(zá)的(de)部署、調優過程, 門檻相對(duì)較高(gāo),難以滿足新增應用(yòng)快(kuài)速上線的(de)需求。 與 GPU 服務器相比,CPU 服務器具備更強的(de)靈活性、敏捷性, 能夠支持大(dà)數據、雲計算(suàn)、虛拟化(huà)等多(duō)種業務的(de)彈性擴展, 方便部署和(hé)管理(lǐ),滿足企業不同業務場(chǎng)景的(de)動态資源需求。 此外,通(tōng)過面向 AI 工作負載的(de)技術特性升級以及性能優化(huà), CPU 已經能夠廣泛滿足用(yòng)戶不同 AI 應用(yòng)對(duì)于算(suàn)力的(de)要求。 解決方案:英特爾® 至強® 可(kě)擴展處理(lǐ)器 + OpenVINO™ 工具套件提升推理(lǐ)性能 爲了(le)構建更高(gāo)效、更具經濟性的(de)在線推理(lǐ)系統,58 同城(chéng)推出 了(le)基于英特爾® 至強® 可(kě)擴展處理(lǐ)器的(de) CPU 推理(lǐ)服務器方案。 該方案除了(le)搭載高(gāo)性能、面向人(rén)工智能應用(yòng)進行優化(huà)的(de)第二代 英特爾® 至強® 可(kě)擴展處理(lǐ)器,還(hái)通(tōng)過 OpenVINO™ 工具套件 進行了(le)性能優化(huà),從而進一步發揮性能潛力。 第二代英特爾® 至強® 可(kě)擴展處理(lǐ)器内置人(rén)工智能加速功能, 并已針對(duì)工作負載進行優化(huà),能夠爲各種高(gāo)性能計算(suàn)工作負 載、AI 應用(yòng)以及高(gāo)密度基礎設施帶來(lái)一流的(de)性能和(hé)内存帶寬。
同時(shí),采用(yòng)矢量神經網絡指令(VNNI)的(de)英特爾® 深度學習(xí)加 速(英特爾® DL Boost)顯著提高(gāo)了(le)人(rén)工智能推理(lǐ)的(de)表現,這(zhè)使其成爲進行深度學習(xí)應用(yòng)的(de)卓越基礎設施。
OpenVINO™ 工具套件支持加快(kuài)部署廣泛的(de)深度學習(xí)推理(lǐ)應用(yòng) 和(hé)解決方案,可(kě)支持開發人(rén)員(yuán)使用(yòng)行業标準人(rén)工智能框架、标 準或自定義層,将深度學習(xí)推理(lǐ)輕松集成到應用(yòng)中,在英特爾® 硬件(包括加速器)中擴展工作負載并改善性能。借助面向 預推理(lǐ)模型的(de)内置模型優化(huà)器(Model Optimizer,MO), 和(hé)面向專用(yòng)硬件加速的(de)推理(lǐ)引擎(Inference Engine,IE)運 行時(shí),OpenVINO™ 工具套件可(kě)在英特爾不同平台上部署并加 速神經網絡模型,能夠在保持精度的(de)同時(shí)顯著提高(gāo)圖像推理(lǐ)速度。
署環境之間的(de)轉換,執行靜态模型分(fēn)析并調整深度學習(xí)模型, 緻力于在終端目标設備上實現最優執行能力。它支持從流行的(de) 框架(包括 TensorFlow/ONNX/模型)到中間數據格式(IR, intermediate representation)的(de)離線模型轉換。推理(lǐ)引擎則 提供統一的(de)跨平台 C、C++ 和(hé) Python API,用(yòng)于推理(lǐ)加速和(hé) 優化(huà)。
OpenVINO Model Server 是高(gāo)性能 K8S 容器化(huà)的(de) AI 服務部 署工具,可(kě)實現便捷高(gāo)效的(de) AI 推理(lǐ)服務部署與運維。該工具 依賴标準的(de) gPRC 和(hé) RESTful 網絡接口,針對(duì)不同的(de) AI 業務 功能,無需重複編寫代碼,即可(kě)實現新模型算(suàn)法服務上線。該 工具同時(shí)集成了(le)高(gāo)度優化(huà)的(de)推理(lǐ)進程,支持英特爾不同硬件平 台資源的(de)調度
驗證:50% 以上的(de)推理(lǐ)性能提升
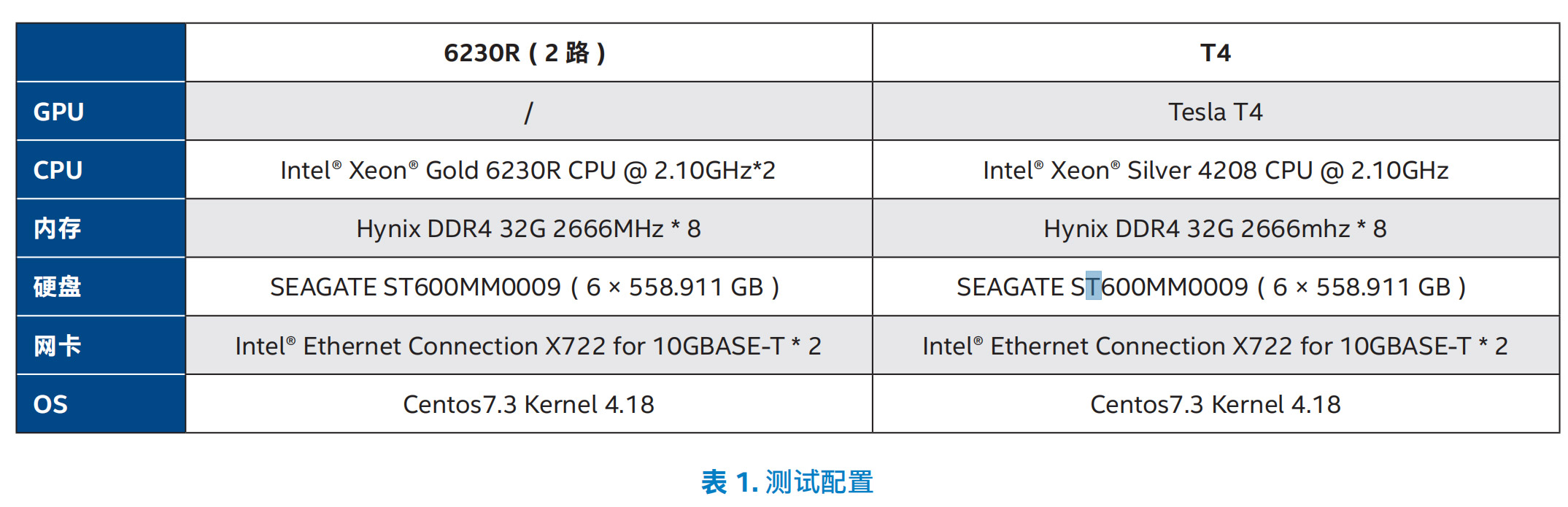
爲了(le)驗證在 CPU、GPU 等不同平台上進行深度學習(xí)推理(lǐ)的(de)性 能以及 TCO 表現,58 同城(chéng)進行了(le)相應的(de)測試,測試采用(yòng)了(le) 基于開源的(de) ResNet50 模型以及基于 Inception 和(hé) ResNet 組 合的(de) ResNeXt 模型,這(zhè)兩種模型皆應用(yòng)在 58 同城(chéng)的(de)實際業 務中。參測的(de)推理(lǐ)服務器分(fēn)别基于英特爾® 至強® 金牌 6230R 處理(lǐ)器以及 T4 GPU,其中,前者爲雙路服務器,測試配置如 表 1 所示
6230R 處理(lǐ)器的(de)平台的(de) ResNeXt 模型推理(lǐ)性能是基于 GPU 平台性能的(de) 1.56 倍,ResNet50 模型的(de)推理(lǐ)性能則是後者的(de) 1.76 倍,能夠滿足 58 同城(chéng)實際業務對(duì)于性能與耗時(shí)的(de)需求。 同時(shí),CPU 平台通(tōng)常有著(zhe)更大(dà)的(de)靈活性與動态擴展的(de)敏捷性, 能夠幫助 58 同城(chéng)更好地爲多(duō)樣化(huà)場(chǎng)景提供支撐。
 czk634@gzyuqiang.com
czk634@gzyuqiang.com
 134-2756-1409 158-7654-7788
134-2756-1409 158-7654-7788
 廣州市天河(hé)區(qū)石牌西路8号1806房(fáng)
廣州市天河(hé)區(qū)石牌西路8号1806房(fáng)



